
Big company problems, GenAI data moats and all-in on full self-driving
7 April 2024 | Issue #20 - Mentions $GOOG, $META, OpenAI, Perplexity, $TSLA

Welcome to the twentieth edition of Tech takes from the cheap seats. This will be my public journal, where I aim to write weekly on tech and consumer news and trends that I thought were interesting.
Let’s dig in.
How Google fumbled AI
Provocative, I know. This was the premise of this week's Big Read from the Financial Times. The story aligns with previous reporting from the FT on Transformers, which I wrote about in July. The company has the expertise and talent to create leading AI technology. However, due to inertia within the large company and a fragmented organizational structure, it has been slow to implement and distribute this tech across its products and services.
Some Google insiders blame the bad publicity on the fact that, as the market leader in search, the company’s mistakes attract outsized attention. According to these people, this makes the company hesitant to move as quickly as others in adopting new AI services, while also subjecting it to disproportionate attention when things, inevitably, go wrong.
Yet cultural and organisational problems also loom large. Current and former Google executives described the company as a series of fiefdoms. Each product line has its own leader, with workers incentivised to make incremental changes to optimise products, rather than radically innovate or work across teams.
Decisions about how to implement generative AI have been spread between divisions responsible for its main search and information services; its computing platforms, including Android and the Chrome browser; cloud computing, which includes Gmail and productivity apps; and YouTube. Former employees describe the mood as one of watching an approaching iceberg but being unwilling or unable to change course.
There’s a dissonance between the AI teams trying to do new things and the search and ads teams “trying to preserve what they have”, says one person with knowledge of the company’s workings. “Google is a nation-state, and the company is run by bureaucrats.”
Pichai admits to challenges caused by Google’s sheer size. “Scale isn’t always good for you,” he said this week, since it makes it harder to “move fast [and] maintain a culture of risk-taking”. He added that “counter-intuitively . . . the more successful things are, the more risk-averse people become.”
Management has recognized its limitations and is actively addressing them. Since Pichai took over, the company, traditionally managed through committees, has relied on consensus decisions. Pichai has now taken a more hands-on role in implementing generative AI in its products. The article mentions that Pichai merged the London-based DeepMind with the California-based Google Brain last April, appointing DeepMind’s co-founder Demis Hassabis as the group's head.
In relation to Hassabis, the Wall Street Journal published an informative profile this week that provides a comprehensive view of the overall situation. It also contrasts with the non-technical DeepMind co-founder, now the head of Microsoft AI, which I discussed in my previous post.
A researcher and software engineer by background, Hassabis often makes public appearances wearing understated crew-neck sweaters and dots his sentences with scientific references. He idolizes the British mathematician Alan Turing, an influential figure in modern AI’s early development who shared an interest in the human brain.
“I view myself as Turing’s champion,” Hassabis said at Stanford University last year. He has long told people that he wants to build artificial general intelligence, or AGI, which can accomplish any human task.
People who have worked with Hassabis described him as a demanding**,** competitive leader with a record of successfully steering researchers toward ambitious goals.
Hassabis began building tech products as a teenager working on videogames. After graduating from Cambridge University with a computer-science degree, he started Elixir Studios, a company that produced a political-simulation game called “Republic: The Revolution.”
“We are re-creating a whole living, breathing country in minute detail,” he told one interviewer when promoting Republic. The game received mixed reviews, and Elixir released one more title before closing two years later.
Hassabis chased even loftier ambitions at DeepMind, which he co-founded in 2010 after completing a cognitive neuroscience doctorate at University College London.
Google purchased DeepMind for about $650 million in 2014 following a bidding war with Facebook1, a deal that valued Hassabis’s stake at roughly $100 million.
Encouraged by Google leaders including co-founder Larry Page to pursue AGI with few worries about cost, Hassabis pushed DeepMind to tackle what he called grand challenges. He told employees they should think about building AGI that could invent discoveries worthy of Nobel Prizes, said people who heard the remarks.
Side note (add as footnote): I didn’t know that Facebook tried to buy DeepMind (and so did Elon Musk). That’s pretty interesting.
This is where some of the dysfunction comes into play.
As the leader of DeepMind, Hassabis was protective of its independence within Alphabet. Jeff Dean, a longtime Google engineering leader who oversaw the Brain division, in recent years clashed with Hassabis about how their two teams should collaborate, said people familiar with the exchanges.
Among other issues, Dean took issue that DeepMind didn’t readily share research that could inform Brain’s work, the people said.
Carl, the Google spokeswoman, said the merger of the Brain and DeepMind teams has been very smooth. Dean and Hassabis have worked closely together for several years and continue to do so, she said.
While Hassabis steered DeepMind toward achievements like drug discovery, other AI research labs such as OpenAI were devoting greater resources to another goal that ended up grabbing the public imagination: building programs that could produce fluent passages of text in a consumer-friendly chatbot.
The launch of ChatGPT caught Hassabis and DeepMind by surprise, said current and former employees. DeepMind had developed a chatbot called Sparrow that was trained to respond more factually than similar products, but Google executives decided it wasn’t as ready for the public as a similar Brain effort called LaMDA.
When Google released its initial response to ChatGPT, a chatbot called Bard, it used LaMDA instead of Sparrow as its underlying technology. Carl said Google later used lessons from Sparrow to help build Gemini.
Hassabis has called this generation of large AI systems “almost unreasonably effective” and predicted that techniques pioneered by DeepMind will be important for building even more powerful systems.
“This is what I’ve always thought, I just wouldn’t have been able to predict the timing,” Hassabis said about the increasing consumer adoption of AI tools.
Hassabis, together with Dean and others at Google, early last year began discussing combining resources to produce an AI system that could rival OpenAI’s technology. Pichai promoted Hassabis months later, putting him in charge of one of the world’s largest collections of AI researchers.
By December, Google largely caught up to breakthroughs made by OpenAI and its primary backer Microsoft with a set of technologies named Gemini.
The company appears to be overcoming these challenges. Reportedly, Gemini Ultra outperforms GPT-4. However, internal conflicts seem to persist within the combined AI organization.
From the FT article
Even within the newly merged organisation, there are factions and divisions that curb entrepreneurialism, one current employee says. They referred specifically to a split between teams working on Gemini and those focused on more fundamental research, with the latter struggling to access compute and other coding resources necessary to scale up AI experiments, resulting in missed opportunities to innovate.
This is understandable. The company is working with researchers who have been free to pursue passion projects without considering costs. Now, they are being asked to focus on profit-making for their parent company and shareholders. This adjustment will take time. Just three years ago, senior managers at DeepMind were negotiating with Google for an independent legal structure for their sensitive research.
PS: this quote below was another thing to ponder on the future of Google’s business model
Google has not disclosed the results of the AI-powered search experiment it has been running since last May, though Pichai claimed in January that it was providing even more links than on traditional Google search results.
Data moats in AI
A good piece from the WSJ came out this week on one of the pillars to gain AI dominance - data.
Companies racing to develop more powerful artificial intelligence are rapidly nearing a new problem: The internet might be too small for their plans.
Ever more powerful systems developed by OpenAI, Google and others require larger oceans of information to learn from. That demand is straining the available pool of quality public data online at the same time that some data owners are blocking access to AI companies.
Some executives and researchers say the industry’s need for high-quality text data could outstrip supply within two years, potentially slowing AI’s development.
AI companies are hunting for untapped information sources, and rethinking how they train these systems. OpenAI, the maker of ChatGPT, has discussed training its next model, GPT-5, on transcriptions of public YouTube videos, people familiar with the matter said.
Companies also are experimenting with using AI-generated, or synthetic, data as training material—an approach many researchers say could actually cause crippling malfunctions.
These efforts are often secret, because executives think solutions could be a competitive advantage.
The data shortage “is a frontier research problem,” said Ari Morcos, an AI researcher who worked at Meta Platforms and Google’s DeepMind unit before founding DatologyAI last year. His company, whose backers include a number of AI pioneers, builds tools to improve data selection, which could help companies train AI models for cheaper. “There is no established way of doing this.”
Data is among several essential AI resources in short supply. The chips needed to run what are called large-language models behind ChatGPT, Google’s Gemini and other AI bots also are scarce. And industry leaders worry about a dearth of data centers and the electricity needed to power them.
AI language models are built using text vacuumed up from the internet, including scientific research, news articles and Wikipedia entries. That material is broken into tokens—words and parts of words that the models use to learn how to formulate humanlike expressions.
Generally, AI models become more capable the more data they train on. OpenAI bet big on this approach, helping it become the most prominent AI company in the world.
OpenAI doesn’t disclose details of the training material for its current most-advanced language model, called GPT-4, which has set the standard for advanced generative AI systems.
But Pablo Villalobos, who studies artificial intelligence for research institute Epoch, estimated that GPT-4 was trained on as many as 12 trillion tokens. Based on a computer-science principle called the Chinchilla scaling laws, an AI system like GPT-5 would need 60 trillion to 100 trillion tokens of data if researchers continued to follow the current growth trajectory, Villalobos and other researchers have estimated.
Harnessing all the high-quality language and image data available could still leave a shortfall of 10 trillion to 20 trillion tokens or more, Villalobos said. And it isn’t clear how to bridge that gap.
Two years ago, Villalobos and his colleagues wrote that there was a 50% chance that the demand for high-quality data would outstrip supply by mid-2024 and a 90% chance that it would happen by 2026. They have since become a bit more optimistic, and plan to update their estimate to 2028.
Most of the data available online is useless for AI training because it contains flaws such as sentence fragments or doesn’t add to a model’s knowledge. Villalobos estimated that only a sliver of the internet is useful for such training—perhaps just one-tenth of the information gathered by the nonprofit Common Crawl, whose web archive is widely used by AI developers.
At the same time, social-media platforms, news publishers and others have been curbing access to their data for AI training over concerns about issues including fair compensation. And there is little public will to hand over private conversational data—such as chats over iMessage—to help train these models.
Incumbent, scaled LLM developers, such as Meta and Google, are in a favorable position. They have the resources and access to proprietary datasets to train their models. As news publishers and social media platforms become more protective of their data, it may pose challenges for new entrants and existing players like OpenAI and Anthropic in training their next-generation models.
Interestingly, OpenAI may be in trouble as YouTube announced that using its videos without permission to develop Sora would violate YouTube's rules. This stemmed from a WSJ interview where OpenAI's CTO, Mira Murati, stated she was unsure whether Sora was trained on YouTube videos and that the company hadn't disclosed the data source. This raises a potential lawsuit risk for OpenAI, although the specifics of copyright law are beyond my expertise.
Meanwhile, Google is opting for a more conservative approach by paying for training data. However, it's doubtful they'll license out their data. The Information published a detailed piece last year on Google's advantage from YouTube.

P.S: If TikTok ever becomes available for purchase, I wager it would hold an immense value for Microsoft. They urgently need more videos for OpenAI's training.
Related: Investors in Talks to Help Elon Musk’s xAI Raise $3 billion, Adding to Industry Arms Race
The future of search
From the FT
Google is considering charging for new “premium” features powered by generative artificial intelligence, in what would be the biggest ever shake-up of its search business.
The proposed revamp to its cash cow search engine would mark the first time the company has put any of its core product behind a paywall, and shows it is still grappling with a technology that threatens its advertising business, almost a year and a half after the debut of ChatGPT.
Google is looking at options including adding certain AI-powered search features to its premium subscription services, which already offer access to its new Gemini AI assistant in Gmail and Docs, according to three people with knowledge of its plans.
Engineers are developing the technology needed to deploy the service but executives have not yet made a final decision on whether or when to launch it, one of the people said.
Google’s traditional search engine would remain free of charge, while ads would continue to appear alongside search results even for subscribers.
But charging would represent the first time that Google — which for many years offered free consumer services funded entirely by advertising — has made people pay for enhancements to its core search product.
Google refutes the claim of working on or considering an ad-free search experience, as mentioned at the end of the article. Instead, it intends to continue developing new premium capabilities and services to improve its subscription offerings. Currently, I estimate Google's US Average Revenue Per User (ARPU) to be around $32/month, based on a variety of assumptions (footnote: US ad revenue of $107bn in 2023, 276m US users according to Semrush). This is compared to its current AI premium pricing of $20/month in the US, which includes access to Gemini in Gmail, Docs, etc., and the Gemini Advanced model in its ChatGPT competitor chatbox.
Given the difference in ARPU, it's understandable why Google might be hesitant to roll out generative AI more broadly. The company's response to the article suggests they may be considering making GenAI-enabled search an addition to its ad revenue, rather than replacing it. Considering that the company only monetizes about 20% of search queries, they could potentially increase revenue if users pay for GenAI-powered search and ask questions outside of that 20% of queries. Alternatively, if users pay for the service but don't use it, although this isn't a sustainable revenue source as users would likely cancel their subscription.
Another intriguing news piece from this week is that Perplexity, an up-and-coming Google challenger, is planning to sell ads.
Generative AI search engine Perplexity, which claims to be a Google competitor and recently snagged a $73.6 million Series B funding from investors like Jeff Bezos, is going to start selling ads, the company told ADWEEK.
Perplexity uses AI to answer users’ questions, based on web sources. It incorporates videos and images in the response and even data from partners like Yelp. Perplexity also links sources in the response while suggesting related questions users might want to ask.
These related questions, which account for 40% of Perplexity’s queries, are where the company will start introducing native ads, by letting brands influence these questions, said company chief business officer Dmitry Shevelenko.
When a user delves deeper into a topic, the AI search engine might offer organic and brand-sponsored questions.
I found it amusing that the company revised their about page to eliminate the statement about being free from the influence of ad-driven models. This may indicate that the company is experiencing slow growth in its premium subscriptions and is exploring methods to generate revenue from its free users, who totaled approximately 10 million as of January 2024. Consumers appreciate free offerings and are often prepared to accept ads as a form of payment. It's a model that simply works.

Under Instagram’s hood
This week, court filings provided a deeper insight into Instagram's financials as its parent company, Meta, requested a judge to dismiss the FTC's antitrust lawsuit against it.
From Bloomberg
Meta Platforms Inc. brought in almost 30% of its revenue from Instagram in the first half of 2022, according to court filings that reveal for the first time how much money the popular photo and video service has generated.
Instagram produced $22 billion in 2020, or 26% of Meta’s total sales, according to documents released in the Federal Trade Commission’s antitrust suit to break up the company. Instagram revenue jumped to $32.4 billion in 2021, or 27% of Meta’s business. The app contributed $16.5 billion in the first six months of 2022.
The numbers confirm that Instagram is growing at a faster pace than other parts of Meta’s social networking universe. They also show the financial success of Chief Executive Officer Mark Zuckerberg’s purchase of the app for just $715 million in 2012.
MBI put up a helpful screenshot on twitter to paint IG’s contribution and growth over time.

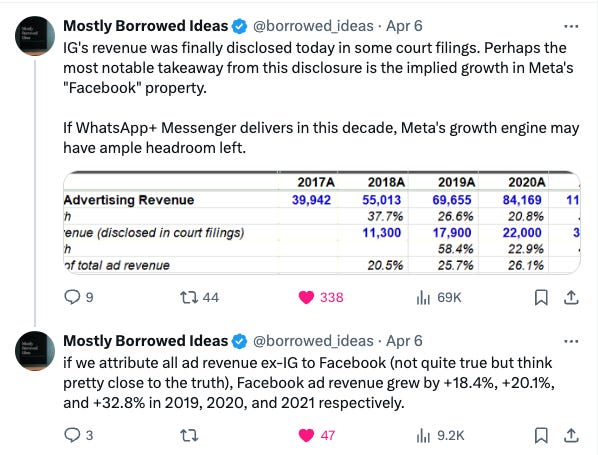
Online estimates put Instagram's revenue closer to $50-60 billion, implying that the business has greater potential than previously thought. This isn't that surprising given that Facebook Blue's daily active users make up approximately 66% of Family DAP (vs ~70%+ of revenue). This suggests that Facebook Blue over-monetizes relative to its user-base, a fact we're generally aware of from surveys.

These extra disclosures could be seen as either positive or negative, depending on one's perspective. To me, it indicates that the company might have a longer runway for growth than anticipated, provided that FB Blue users stay engaged. However, this might be more challenging to monitor in the future, as the company recently announced they would no longer provide separate Blue metrics.
Also, the stat below demonstrates that Instagram's acquisition is among the greatest of all time. The company's estimate of IG standalone value is probably underestimated by 3-4 times.
“Meta said it has invested more than $1 billion in Instagram since the 2012 acquisition, introducing more than 30 new features and services on the platform. Instagram generated revenues of $32.4 billion in 2021 and estimates of the company’s standalone value are between $80 billion and $100 billion, the company said.”
Tesla pulling out of the low-end market
From Reuters
Tesla has canceled the long-promised inexpensive car that investors have been counting on to drive its growth into a mass-market automaker, according to three sources familiar with the matter and company messages seen by Reuters.
The automaker will continue developing self-driving robotaxis on the same small-vehicle platform, the sources said.
The decision represents an abandonment of a longstanding goal that Tesla(TSLA.O), chief Elon Musk has often characterized as its primary mission: affordable electric cars for the masses. His first “master plan”, opens new tab for the company in 2006 called for manufacturing luxury models first, then using the profits to finance a “low cost family car.”
Musk has since repeatedly promised such a vehicle to investors and consumers. As recently as January, Musk told investors that Tesla planned to start production of the affordable model at its Texas factory in the second half of 2025, following an exclusive Reuters report detailing those plans.
Tesla’s cheapest current model, the Model 3 sedan, retails for about $39,000 in the United States. The now-defunct entry-level vehicle, sometimes described as the Model 2, was expected to start at about $25,000.
Tesla did not respond to requests for comment. After the story was published, Musk posted on his social media site X that "Reuters is lying (again)." He did not identify any specific inaccuracies.
If true, this suggests a significant shift in the company's strategy. The mass auto market (below ~$45k in the US) accounts for about 80% of sales volumes in the country. If we apply this globally, Tesla is competing in a premium auto market of about 18m vehicles (mass market is <$32k in Europe and <$14k in China, according to Bernstein), implying a 10% share.
This strategy suggests the company is banking heavily on its robotaxi/FSD (Full Self-Driving) feature, as growth in vehicle sales may slow down due to increasing difficulty in gaining more market share in the premium segment. Investors seem to believe that the company's future lies less in vehicle deliveries and more in licensing its autonomous driving technology and battery charging network.2
Even after a ~60% drop from all-time highs, the stock still trades at a significant premium compared to its auto industry peers. From my experience, the best stock setups occur when optionality is being priced as exactly just that - optionality (for e.g. Meta trading at or below market multiples while losing $20bn/year on Reality Labs). If the bet doesn't pay off, the demanding premium multiple could lead to a painful de-rating.

Chart generated and financial data obtained from Koyfin. Sign-up using my link for 20% off.
Disclosures: I’m long Meta and Alphabet and short Tesla.
That’s all for this week. If you’ve made it this far, thanks for reading. If you’ve enjoyed this newsletter, consider subscribing or sharing with a friend
I welcome any thoughts or feedback, feel free to shoot me an email at portseacapital@gmail.com. None of this is investment advice, do your own due diligence.
Tickers: GOOG 0.00%↑, META 0.00%↑, TSLA 0.00%↑
I didn’t know that Facebook tried to buy DeepMind (and so did Elon Musk). That’s pretty interesting.
Slower deliveries will also mean a smaller number of vehicles on the roads for RLHF.
I don't buy the data moats in AI as much as everyone else. Not all data is the same, the quality of data matters a lot - ex: textbooks vs twitter vs facebook text. You can learn a lot more "useful" things from textbooks vs random text on facebook. So, I don't think the data in TikTok or facebook is very useful.
Curating data has been a big thing (Ex: TextBooks are all you need https://arxiv.org/abs/2306.11644) and so is synthetic data Ex: train on a video game to learn physics, or train on LLM outputs in clever ways (Ex: Q*). Don't think facebook/instagram/tiktok/nytimes data is anywhere as useful as people claim to be.
Hey, I just took over your friend’s phone. I can see from your recent texts that you have a problem. How can I help? I think this is the beginning of a beautiful friendship.